Emily Qiu

Master of Analytics | UC Berkeley
About
Hi, I’m Emily — a data science professional with a BSc in Applied Mathematics from the University of Edinburgh and a recently completed Master’s in Analytics from UC Berkeley. My academic and project experience bridges mathematical rigor with real-world applications, from predictive modeling and NLP to optimization, recommendation systems, and behavioral simulation.
I’m passionate about uncovering actionable insights through data — whether by designing machine learning models, architecting data pipelines, or visualizing complex patterns for decision-making. My work spans domains like e-commerce, sustainability, finance, and transportation, and I’m always eager to explore new technologies and frameworks that drive smarter systems.
I enjoy both independent deep work and collaborative problem-solving, and thrive in environments where intellectual curiosity, experimentation, and cross-functional teamwork are valued. I approach every project with a learning mindset and a focus on impact — combining technical precision with clear communication.
This portfolio showcases the projects, tools, and techniques that reflect my growth, adaptability, and dedication to building meaningful, data-driven solutions.
Table of Contents
- About
- Portfolio Projects
- Python
- MATLAB
- SQL
- R
- Excel / Google Sheets
- Tableau—> go to Tableau..
- Power BI
- Certificates
- Contact
Portfolio Projects
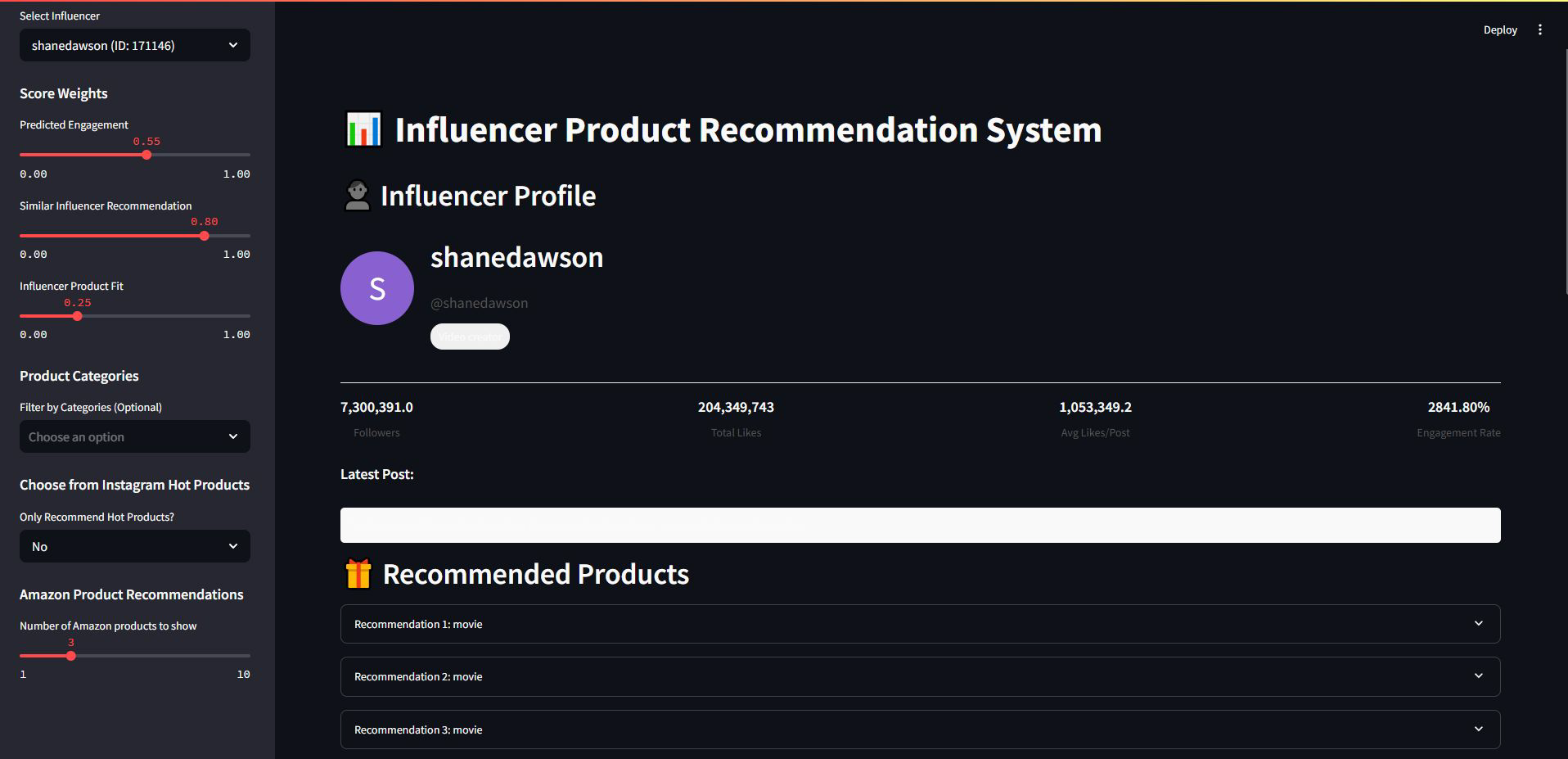
Online Influencer Product Recommendation System
Code: Online Influencer Product Recommendation System
Final Presentation: Presentation
Goal: To develop a multi-stage, data-driven product recommendation system for social media influencers, aimed at maximizing engagement and sales potential through personalized product placements.
Description: This project focused on building a full-stack recommendation engine that identifies and ranks suitable Amazon products for social media influencers based on audience engagement, influencer profile, and market trends. The system integrates multiple machine learning techniques across three main stages:
1) Recall Stage:
Utilized influencer-based collaborative filtering by computing caption similarity (TF-IDF + cosine similarity) and follower overlap via KNN (k=11) to identify a pool of relevant products. Historical influencer engagement and popularity trends were also incorporated to ensure diversity and completeness of the candidate set.
2) Fine Ranking Stage:
Relevance scores were computed using a hybrid scoring model:
$\text{Score}_{\text{user, product}} = \alpha \times \text{Predicted Likes} + \beta \times \text{Collaborative Filtering Score} + \gamma \times \text{User-Product Embedding Similarity}$
A LightGBM model was trained on multi-dimensional features (influencer attributes, product metadata, timing) to predict post engagement (likes/comments), achieving an $R^2 = 0.507$.
4) Re-Ranking Stage:
Applied SBERT embeddings and FAISS for fast similarity search between influencer captions and product descriptions. An autoencoder architecture learned a shared latent space for aligning influencers’ post embeddings with product metadata vectors, enabling efficient top-N product recommendations.
Skills: Collaborative filtering, content-based recommendation, supervised learning (LightGBM), feature engineering, embedding models (SBERT), autoencoders, model evaluation, Streamlit UI development.
Technology: Python (scikit-learn, LightGBM, PyTorch, FAISS, NLTK), SBERT, PCA, Streamlit, Amazon Reviews dataset, Instagram API.
Results:
- The LightGBM engagement model demonstrated strong predictive accuracy for likes based on influencer behavior and posting time.
- Recommender favored fashion and entertainment products, while identifying high engagement potential in underrepresented categories like health and personal care.
- Influencer engagement patterns showed optimal post timing around late evenings and Mondays.
- A prototype dashboard built in Streamlit allowed influencers to customize recommendation weights and receive predicted likes, category fit, and best posting time.
This system highlights end-to-end ML pipeline design, integration of structured and unstructured data, and real-world applicability in influencer marketing and recommendation systems.
Calyber: A Shared Rides Pricing and Matching Game
Code: Calyber Game
Report: Calyber_Final_Report.pdf
Goal: To develop a scalable, profit-aware, and computationally efficient joint pricing and ride-matching policy for a simulated ride-hailing platform using real-world data.
Description: This project tackled the dual challenge of dynamic pricing and real-time rider matching within the Calyber shared mobility platform. Leveraging historical ride data from Chicago, the team engineered a contextual multi-armed bandit algorithm and a profit-maximizing greedy matcher to simulate intelligent dispatch behavior.
The pricing policy used a contextual Beta-Bernoulli Thompson sampling bandit, trained offline, to learn rider price sensitivity across origin-destination pairs, pool sizes, and wait-time buckets. The model balanced exploration and exploitation under uncertainty, enabling adaptive, interpretable pricing within sub-5ms runtime limits.
On the matching side, a marginal-gain greedy algorithm was implemented. It assessed every new rider’s incremental profit potential with existing waiting riders and executed matches only when doing so improved overall system profit. This ensured matches were not only feasible but also financially optimal.
Skills: Bayesian machine learning, simulation modeling, dynamic pricing, real-time decision-making, matching algorithms, performance benchmarking.
Technology: Python (NumPy, pandas, scikit-learn), simulation frameworks, Git.
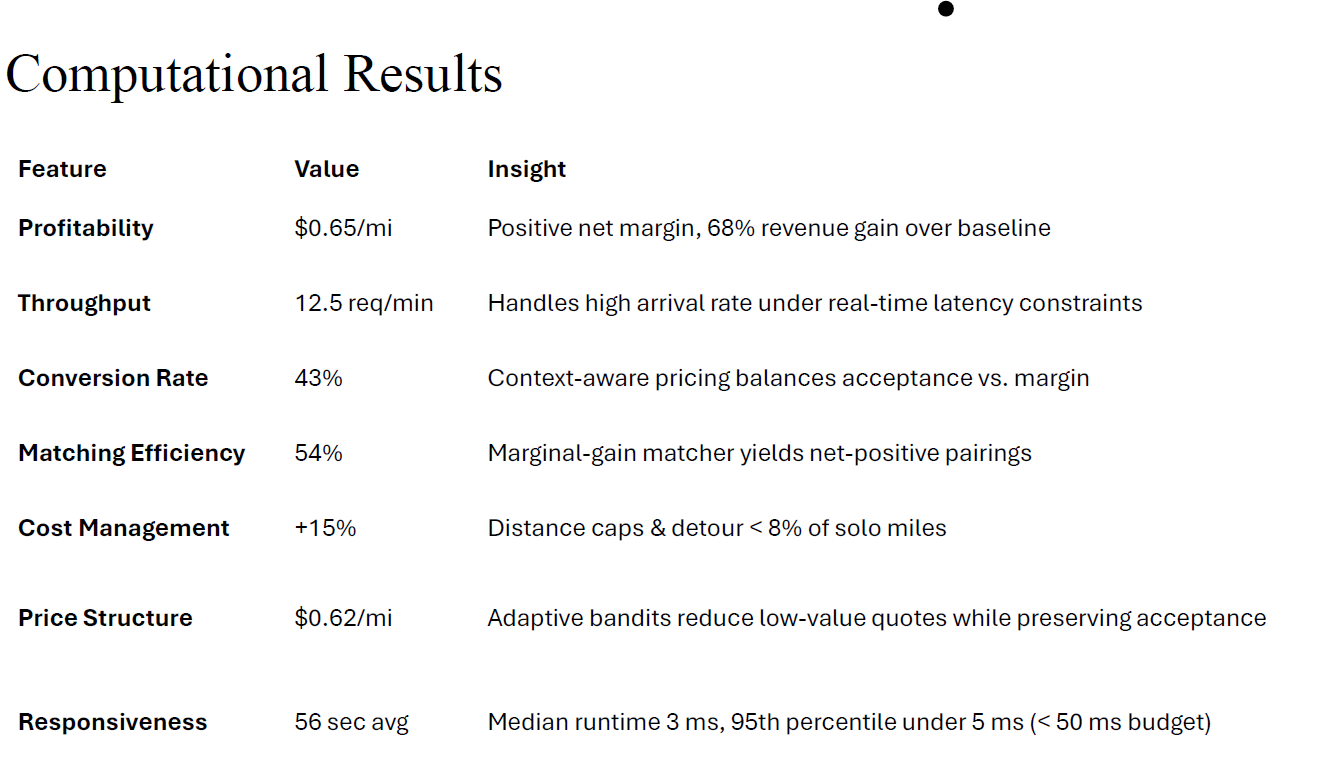
Results:
- Achieved a $0.65/mi net profit, up from a negative baseline.
- Reached a 43% rider conversion rate, demonstrating effective pricing.
- 54% match rate with high cost-efficiency (detours under 8% of solo miles).
- Runtime latency kept under 5ms per decision, meeting real-time constraints.
This project demonstrates the real-world application of ML algorithms for supply chain and transportation optimization, blending statistical modeling with computational performance for deployment-ready solutions.
The Traveling Salesman Problem (TSP)
Code: The Traveling Salesman Problem
Report: TSP_Project_Report.pdf
Goal: To assess various algorithmic strategies against the TSPLIB dataset to identify the most effective approaches for symmetric TSP instances.
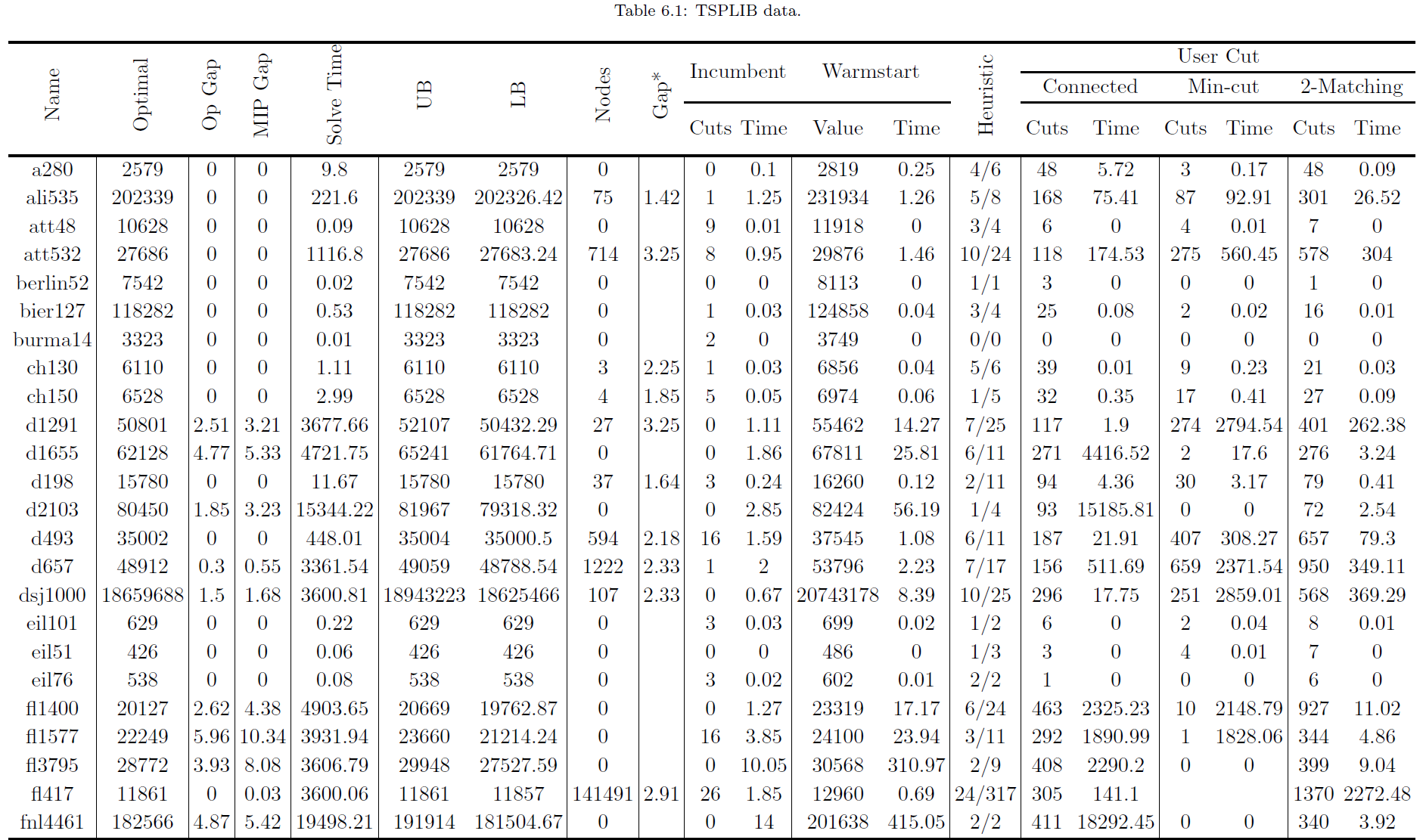
Description: The project implemented a branch and bound algorithm for solving the Traveling Salesman Problem (TSP) using Python 3.10 and IBM’s CPLEX version 22.1.1.0. The DOcplex API facilitates communication between our code and CPLEX, leveraging callbacks to interact during the algorithm’s execution.
Cutting plane techniques, including sub-tour elimination constraints (SECs) and 2-matching inequalities, were implemented to handle fractional solutions. Integer Programming (IP) gap monitoring guided termination by tracking the difference between the incumbent solution and the lower bound.
Heuristic algorithms were implemented in two ways: 1) Full construction at root node (warm-start) – construct a feasible solution from scratch when no incumbent solution has yet been identified; 2) Refinement of a current solution: create integer solutions from fractional solutions or refine current integer solutions.
Nearest Neighbour and two-opt algorithms were selected for heuristic application, complemented by optional algorithms: Constuctions (cheapest insertion, farthest insertion, random insertion, greedy algorithm, nearest insertion, nearest neighbor), improvements (2-opt, 3-opt).
The approach emphasized systematic node exploration and pruning to efficiently converge to optimal TSP solutions, ensuring a robust and efficient solution process integrating advanced branch and cut techniques with heuristic methods.
Skills: linear programming, data handling and manipulation, optimization techniques, algorithm development and optimization, statistical analysis, heuristic methods, performance monitoring, computation efficiency, software integration.
Technology: Python (Numpy, Matplotlib, cplex, docplex).
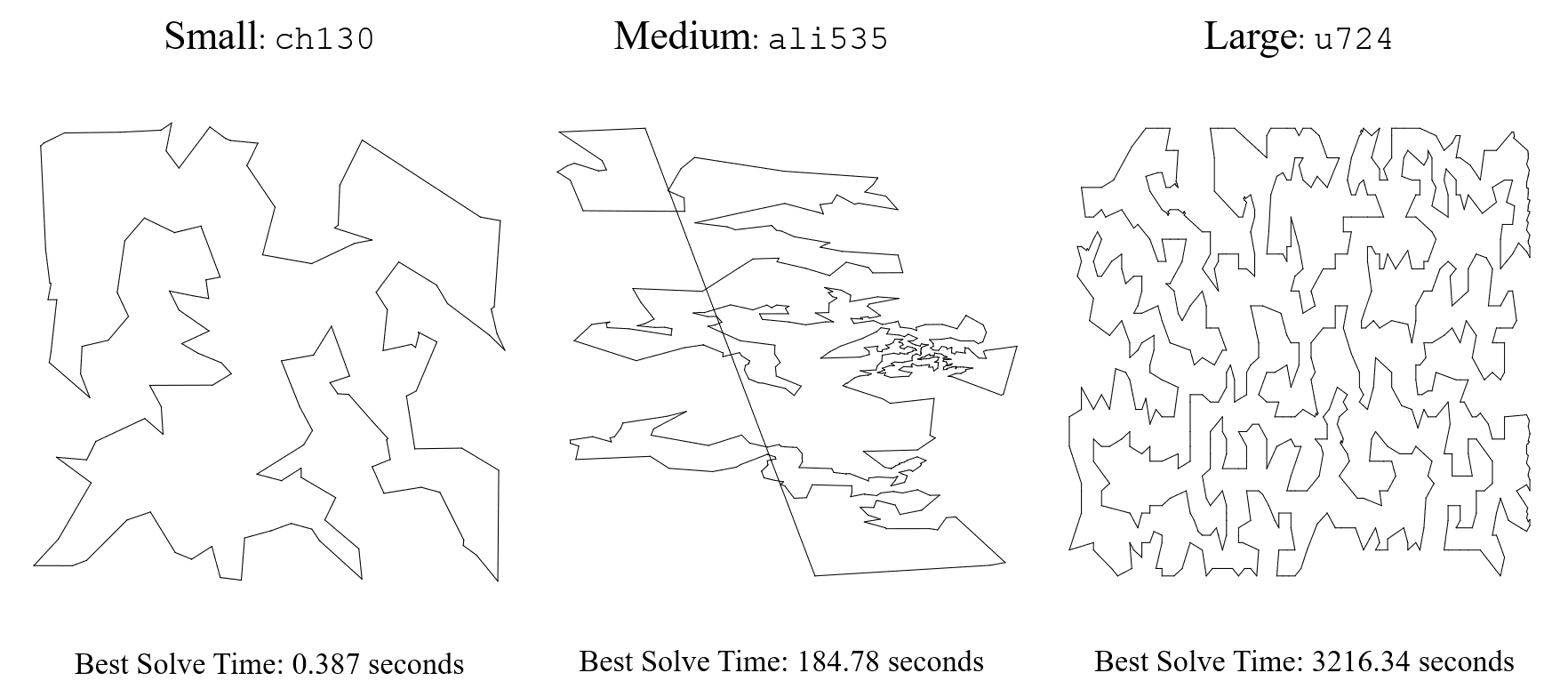
Results: The implementations led to significant improvements in solve time TSP instances with more than 200 nodes. Smaller TSP instances are fairly well solvable using the core branch and cut algorithm; thus the augmentations slowed these instances down (however with solve times of under 2 seconds the difference is practically insignificant).
There is an average of 84.58% improvement in solve time of the medium and large TSP instances from adding all of our augmentations simultaneously and 60% improvement in the solution quality for larger TSP instances which did not solve to optimality. This suggests that our augmentations were indeed successful.
Notable observations from the data:
- Warm-start ineffective when also implementing heuristic callback
- The pairing of two matching and connected components leads to terrible solution attempts; specifically worse than adding no implementations at all
We ran the full implementation suite with a 1-hour time-limit on a set of 89 problems from the TSPLIB
- This was all problems that our machine had enough memory to load in:
- The key observation from this data is that all instances on a specific node size are not equal
Machine learning approaches for super-resolution problems
Code: Machine learning approaches for super-resolution problems
Report: ML_Approaches_for_Super_Resolution_Problems_Report.pdf
Goal: To investigate the feasibility of generating high-resolution satellite images from lower-resolution inputs by integrating machine learning techniques using python.
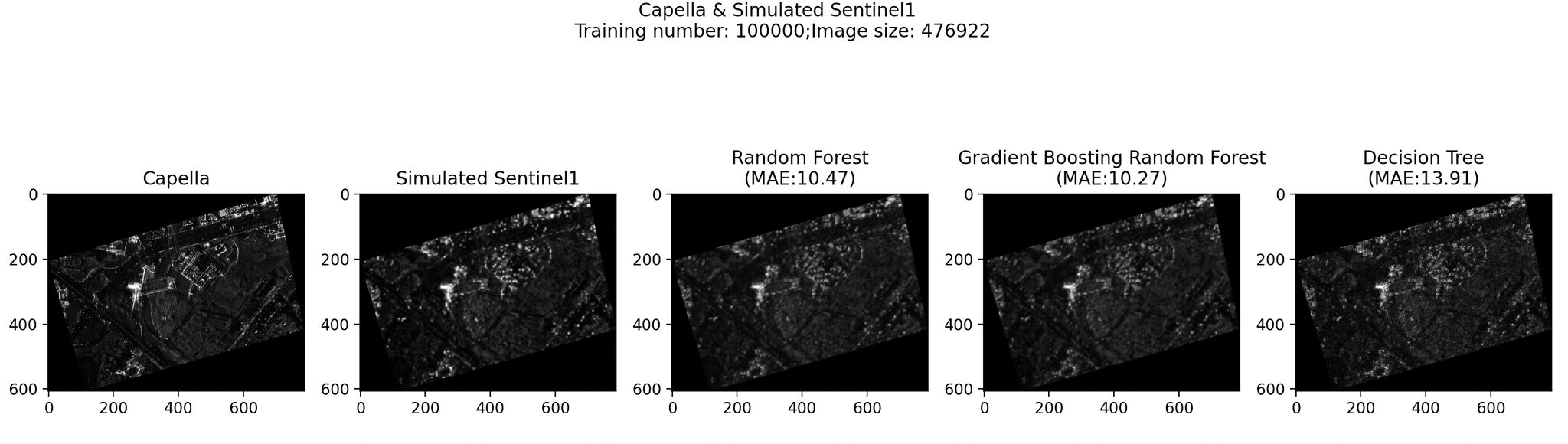
Description: The project centered on analyzing Synthetic Aperture Radar (SAR) satellite imagery data from Sentinel-1 and Capella Space, specifically within the 2023 Turkey–Syria earthquakes region.
The metadata from SAR satellite imagery includes information about the imaging parameters (radiometric resolution, corrdinate reference system, radiometric accuracy) and acquisition conditions (orbit information, sensor configuration, swath width).
The project invoved loading the data, cleaning and preprocessing it by applying Geographic Information Systems (GIS) tools like Quantum GIS. Tasks included refining image quality through noise removal, radiometric calibration, and speckle filtering processes.
Mathematical concepts such as bilinear interpolation and entropy comparison were employed for proper image resizing and pixel alignment. Alternative approach for bilinear interpolation method was also implemented: the deep learning model - Enhanced Deep Residual Networks for Single Image Super-Resolution (EDSRx2) model.
Machine learning models (Random Forest, Gradient Boosting, Decision Tree) were selected to perform image upscaling. Models were further enhanced through multidimensional feature vectors and Principal Component Analysis. Feature vectors includes surrounding pixel values, RGBI band pixel values from Sentinel-2, calculation of GNDVI, NDVI, and Building index, and integration of building layer from OpenStreetMap.
Skills: data preprocessing, machine learning, deep learning.
Technology: Python (skimage, matplotlib, rasterio, numpy, scipy, PyTorch).
Results: The investigation reveals challenges due to limited high-resolution SAR images like Capella’s.Super resolution methods were relied to upscale low-resolution data, which hinges on their effectiveness. Access to more high-resolution SAR images tailored to specific regions could significantly enhance our results.
Approach pairing Sentinel-1 data with Capella data shows promise with its efficient use and initial positive outcomes, suggesting a need for further exploration and integration of tailored feature layers to improve model performance.
.jpg)
.jpg)
Machine Learning Explorer Application (MLx.m)
Code: The project code is restricted from public access due to its status as an educational application currently in development. It is designated for private use within the university under the oversight of the professor.
Goal: To integrate a new data type (poker hands dataset) to the application; to create new App features by enabling accuracy and loss metrics, along with dynamic confusion chart for models training, testing and deploying automatically.
Description: The pokerhand dataset comprises thousands of entries, each representing a sequence of five playing cards characterized by their suit and rank values. The dataset includes attributes such as the suit and rank of each card, encoded numerically (1-4 for suits representing Hearts, Clubs, Diamonds, and Spades, and 1-13 for ranks representing Ace through King). Each entry ends with a class label ranging from 0 to 9, indicating the type of poker hand formed by the five cards, such as “Royal Flush” or “Two Pairs”.
The tasks include loading the dataset, visualizing its structure, developing feature selection algorithms, implementing normalization/scaling techniques, preprocessing the data for input into machine learning models, conducting model training and evaluation, optimizing parameters, and visualizing data insights.
Skills: Machine Learning, data preprocessing, data analysis, data visualization.
Technology: MATLAB (object-oriented coding, graphics and GUI toolbox, statistics and machine learning Toolbox)
Results: The Poker Hands dataset is successfully integrated, which expands the application’s functionality. This enhancement introduced automated computation of accuracy and loss metrics, providing detailed insights into model performance during training, testing, and deployment phases.
Additionally, the integration facilitated dynamic generation of confusion charts, enabling real-time visualization and analysis of classification results, thereby enhancing the application’s capability to evaluate and refine predictive models effectively.
/MLx app.png)
/confusion_chart.png)
The EZ Trainer Database
Code: The EZ Trainer Database
Goal: To design and implement a comprehensive relational database for EZ Gym, integrating membership, operations, workout logging, and nutritional tracking, along with developing a VR-integrated fitness solution.
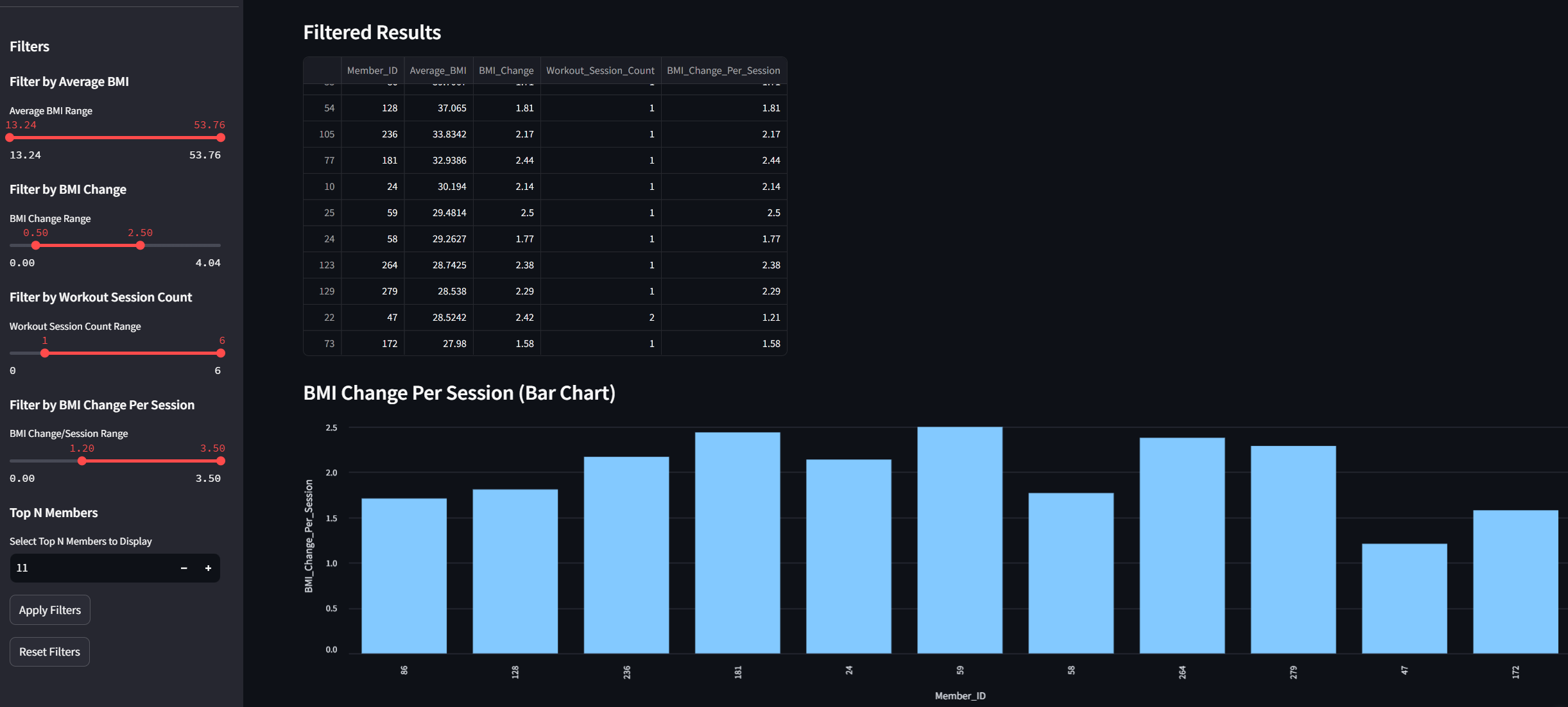
Description: The project involved developing a database system for EZ Gym, a fitness center that merges VR technology with personalized training experiences. The database supports various functions, including membership management, staff scheduling, and inventory management. Additionally, the system tracks workout and nutrition data for personalized health recommendations.
Skills: Database Design and Management, SQL Query Optimization, Data Analysis and Visualization, Integration of VR technology in fitness solutions
Technology: SQL for relational database management MongoDB for handling semi-structured data Python for data analysis and backend operations Jupyter Notebook for data manipulation and visualization
Results: Successfully implemented a scalable database that centralizes user information, simplifies administrative tasks, and supports advanced data analytics for personalized service delivery. Enhanced member engagement and operational efficiency were achieved through the integration of VR and detailed nutritional and workout tracking.
Dashboard: https://ez-training.streamlit.app/
Certificates
- App Building Onramp
- MATLAB Onramp
- Machine Learning Onramp
- Object-Oriented Programming Onramp
- Data Analysis Using Python
- Operations Analytics
- Customer Analytics
- What is Data Science?
Contact
- LinkedIn: @emily-qiqiu
- Email: emily_qqiu@outlook.com